
Então, devo reconhecer que o título é propaganda enganosa. O Git não é simples. Ele é complexo e difícil de aprender. O Git é uma ferramenta poderosa, e a sua complexidade tem a ver com essa sua potência e flexibilidade.
Mas, não é impossível estabelecer um fluxo de trabalho básico que, prescindindo de várias das suas infinitas possibilidades, permita escrever código com maior eficiência e de forma colaborativa. Essa postagem pretende dar enfase ao processo mais do que aos comandos.
Commits
O Git é um sistema de controle de versões. Você quer conservar um histórico com os pontos mais importantes do processo de construção de um projeto de código. Você quer a possibilidade de voltar atrás quando precisar, por exemplo, para retomar uma ideia que foi abandonada; ou corrigir um bug da versão anterior; etc.
Se você está trabalhando em colaboração com outros programadores, a cada tanto, o código deles ou o seu, vai ter de ser integrado com o código principal. Essa integração pode funcionar ou não. De novo, a possibilidade de voltar ao estado prévio resulta imprescindível.
Os commits são esses pontos chave no processo. Quando você faz um commit, você manda o Git pegar o estado atual do projeto todo e salvar, “por qualquer coisa”. Agora você pode seguir na frente sem o risco de perder o seu trabalho se o que fizer a continuação não dar certo.
O Git identifica cada commit de forma unívoca por médio de um número compridão (SHA-1 hash). Esse número é muito bom pro Git, mas ele não é muito útil pra nossa pobre memória humana. Daí que é fundamental acompanhá-lo com um título significativo e uma mensagem explicativa. Esses lembretes não apenas vão ajudar você, eles também serão a única forma de seus colegas ficarem sabendo o que você quis fazer com esse commit.
Não existe uma fórmula para determinar quando um commit deve ser feito. A decisão é uma mistura de experiência, bom senso e acordos prévios feitos junto aos colegas do time. Ele tem que fazer sentido, tanto pra você como pros outros envolvidos.
Branches
O processo de escrever código é qualquer coisa menos linear. As ideias vão e voltam, tentativa e erro, novos requerimentos, optimizações, encaixar as partes, debugar, fazer tudo de novo, retomar código que ficou parado, integrar código, etc. E ainda mais quando o código é feito por um time. E ainda mais quando tem um gerente no meio…
Nessas condições, o processo rapidamente se transforma numa árvore com um tronco principal (master) e um maior ou menor número de galhos (branch), dependendo de cada projeto. Esses galhos podem se manter relativamente independentes do tronco principal ou se misturar (merge) com ele num determinado ponto. 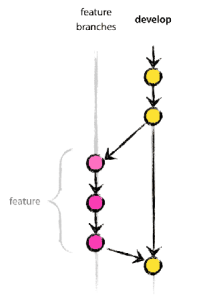
Cada branch é uma sequência linear de commits. Cada branch nasce de um commit, ou seja de um determinado momento no processo total. E todas elas podem se integrar (merge) com as outras. O negócio pode ficar bem complicado, mesmo, e precisa ser bem planificado.
Em um workflow simples (que essa era a ideia dessa postagem), se eu quiser fazer uma contribuição a um projeto de código, eu vou criar um branch, vou trabalhar nessa contribuição e, quando achar que está pronta para ser integrada, vou fazer um merge.
Pull & Push
A possibilidade de armazenar um repositório Git num serviço nas nuvens permite os desenvolvedores clonarem esse repositório nos seus computadores, trabalharem nele de forma local, remeterem o código de volta pro repositório remoto e, a sua vez, integrarem o que outros colaboradores tem acrescentado. Tudo isso faz do Git uma ferramenta essencial para o trabalho colaborativo.
O serviço de armazenamento online de repositórios Git mais popular é o GitHub. Importantes projetos, sobre tudo de software livre, estão lá. E é possível criar uma conta gratuita e começar a trabalhar na hora. A conta premium permite tornar esses repositórios privados, do contrário, eles serão públicos.
O fluxo de trabalho seria o seguinte: 
- Alguém cria um repositório e disponibiliza ele online no GitHub
- Os colaboradores fazem forks nas suas contas e clonam localmente (clone)
- As modificações locais são remetidas (push) ao fork
- Quando prontas, é solicitado um pull request
- Se o pull request for aprovado, as modificações são integradas (merge) ao repositório oficial
- Os colaboradores sincronizam seus repositórios locais (pull)
Alguém, provavelmente o líder do projeto cria um repositório e bota ele no GitHub. Os colaboradores fazem um fork (um clone do projeto na conta pessoal do GitHub), e logo clonam o fork localmente para poder trabalhar nos seus computadores. Nesse momento, existe uma copia do projeto no repositório oficial (online), outra em cada uma das contas dos colaboradores (online), e outra no computador de cada um deles (local).
Quando um colaborador faz modificações na sua copia local e acredita que estejam prontas para serem integradas ao projeto geral, ele sincroniza (faz um push) a copia local com o seu repositório online (o fork) e solicita um pull request (um merge do que ele tem no seu repositório online com o que está no repositório oficial). Se o líder aprovar, o repositório oficial agora possui as modificações feitas pelo colaborador, então, todos os membros deveriam sincronizar seus repositórios locais (pull) para ter sempre a última versão do que está sendo feito.
